Switch Models Mid-Conversation: No Restarts, No Lost Context


Want a cheaper model? Paste your requirements again.
Want a stronger model? Re-explain the whole context.
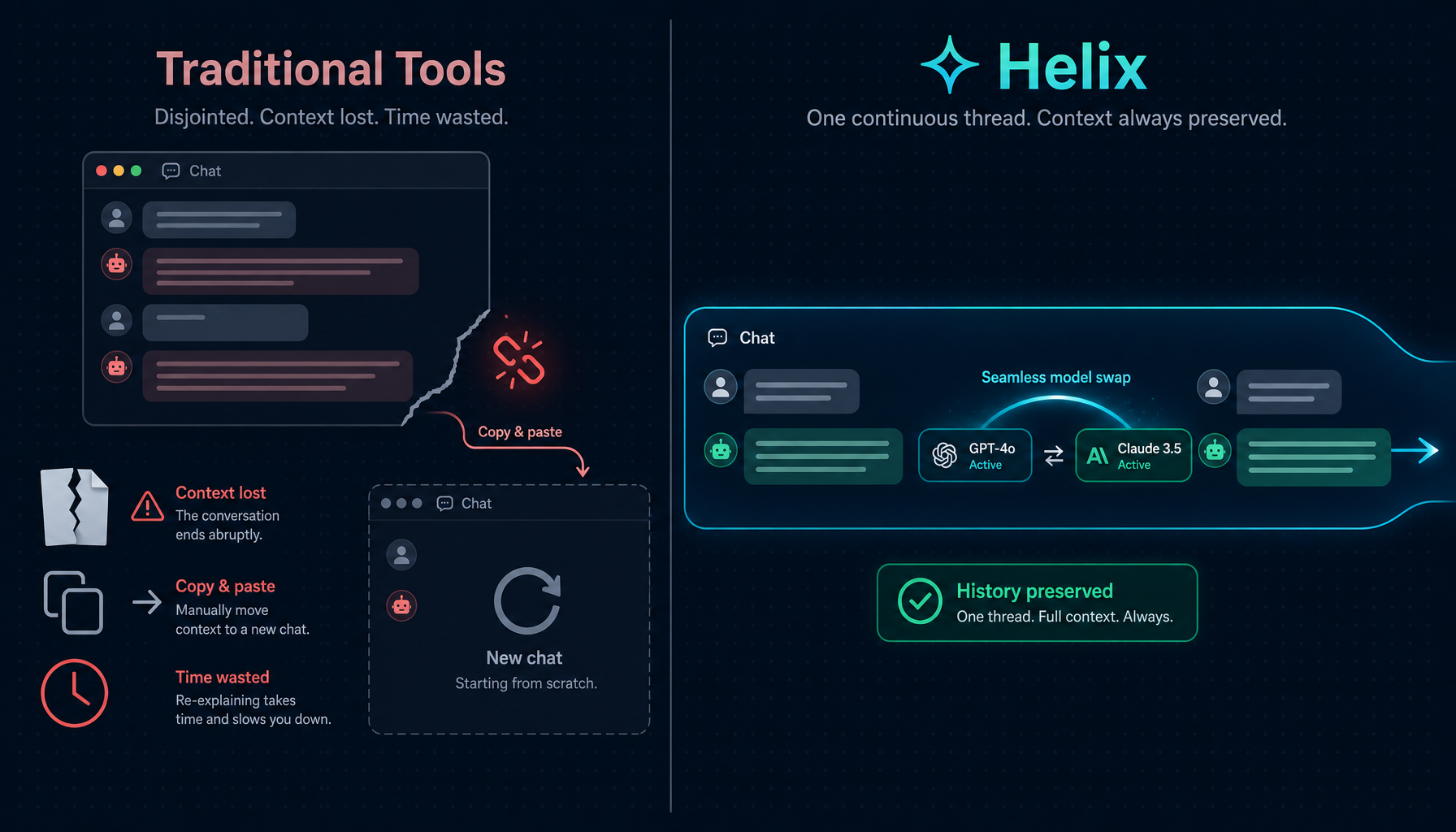
That is what switching models looks like in most AI tools today.
Switching models mid-session sounds simple. In most systems, it actually means: start over.
You pick a model at the beginning of a conversation. You build context — twenty messages deep, a dozen tool calls, a pile of file reads. Then you realize the model is too slow, too expensive, or missing a capability you need. Your options: abandon the session and start fresh, or keep going with the wrong tool for the job.
Helix is not designed that way.
In Helix, the model is the session's current engine, not its identity. Users can change models at any point in a conversation — the same history, the same tool config, the same thinking context, just a different engine driving the next message.
This is the concrete product expression of the position stated in the Helix introduction: "the session is the unit of continuity; the model is just the current engine."
1. Committing to a model upfront is a structural waste
Every model has a different cost-capability tradeoff.
A model that's ideal for deep reasoning on a complex architecture problem is expensive for quick drafting work. A fast, cheap model that handles routine edits well falls short when you need multi-step reasoning across a large codebase.
Real work doesn't fit neatly into one category.
A coding session often starts with exploration — reading files, understanding structure, asking clarifying questions — and ends with implementation work that demands more capability. Or the reverse: start with a powerful model on the hard part, then switch to something faster for the follow-through.
The conventional approach forces users to make this choice once, at session start, with the least information they will ever have about what the task actually requires.
This isn't a limitation of the models themselves. It's the product form putting "pick the model" at the wrong moment.
2. Helix model switching: traditional way vs Helix way
In Helix, the model selector is always available in the chat toolbar. Users can change it at any point during a conversation.
The next message they send uses the new model — with full access to everything that happened before.
No reset. No re-explaining. No "let me catch you up."
The conversation history travels with the user across model changes. This is not a prompt injection trick where the previous messages are summarized and handed off — the actual message history is transferred to the new model directly, so it has the same context depth as if it had been in the conversation from the start.
Helix exposes model switching at three different levels of granularity:
- Default model — the account- or workspace-level default engine; new sessions inherit from here
- In-session switch — replace the engine at any point mid-conversation; takes effect on the next message
- Per-tool-call routing — certain specialized tools (lightweight prompts, code completion) can use a cheaper model than the main conversation, routed automatically by the Agent system
All three levels share the same underlying switching mechanism; they differ only in where the switch is triggered.
3. Three switching paths
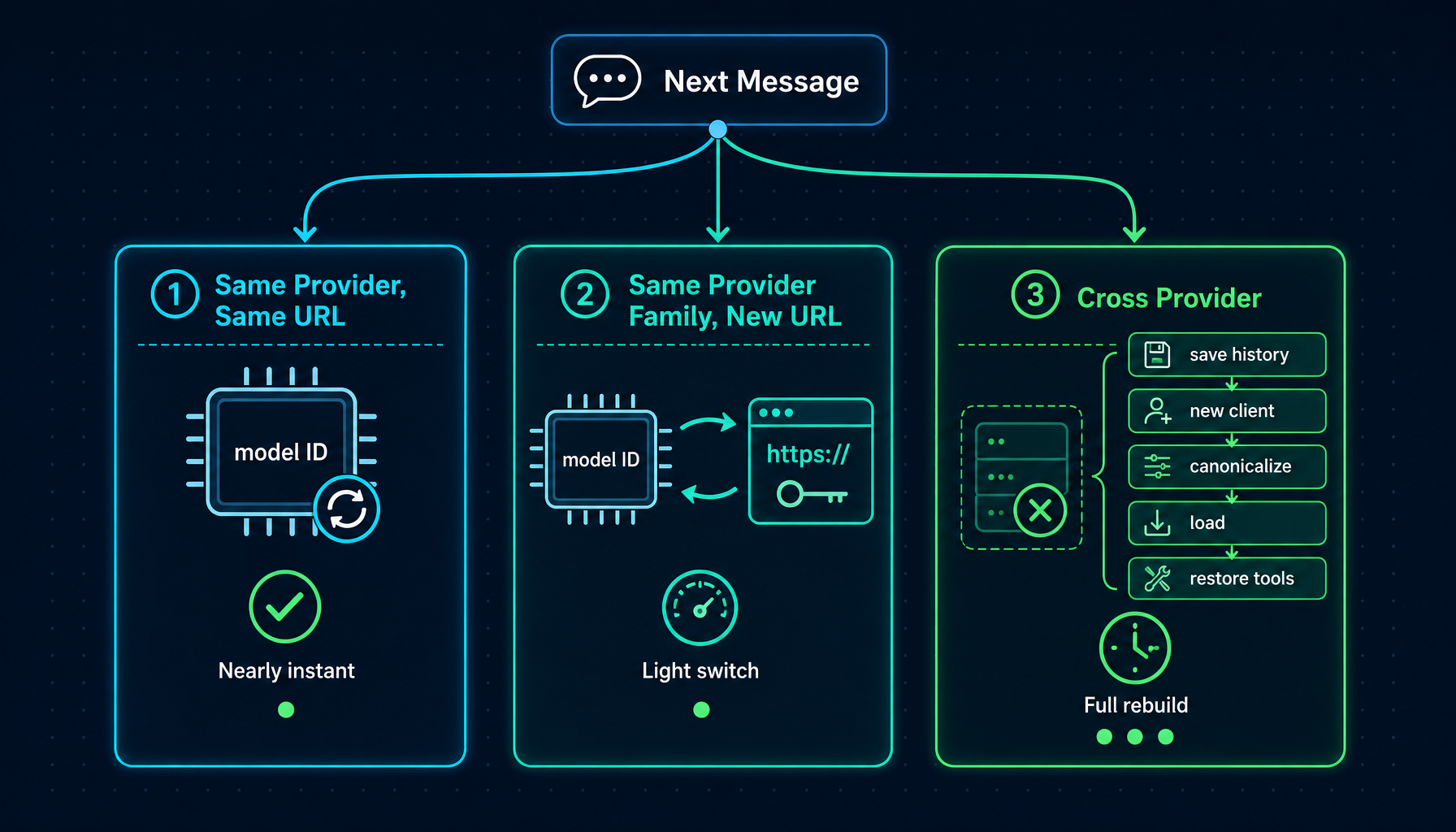
Not all model switches are the same. Helix handles three distinct scenarios differently, based on what needs to change under the hood.
Same provider, same base URL (e.g., gpt-4o → gpt-4.1): the LLM session updates its model ID in place. The existing connection, tool configuration, and message history are untouched. This is nearly instantaneous.
Same provider family, different base URL (e.g., switching between two custom OpenAI-compatible endpoints): the session updates its model ID, base URL, and API key. No Runner rebuild required.
Cross-provider switch (e.g., GPT-4o → Claude Sonnet, or any model → CLI mode): a full Runner rebuild happens. The message history is extracted from the old Runner, sanitized, and loaded into the new one. This is the most interesting case — and the one worth understanding in detail.
At the engineering level, "light switches" and "heavy switches" travel different code paths. From the user's point of view, they are all the same single click in the toolbar. Hiding that complexity is part of what the product is for.
4. What happens to your conversation history on a cross-provider switch
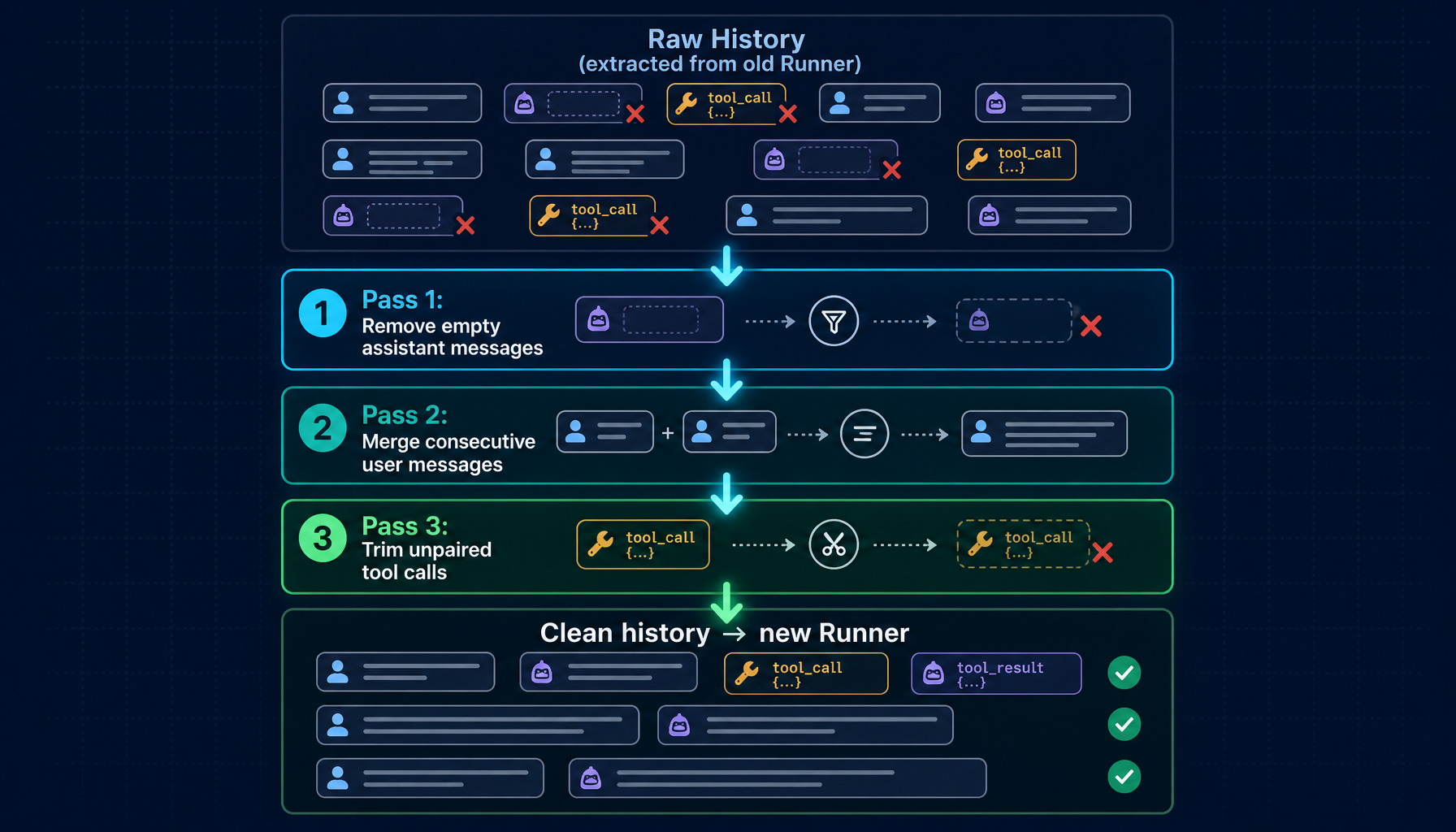
When you switch across providers, Helix performs a canonicalization pass on your message history before handing it to the new model.
Here's why that's necessary.
Different providers have subtly different requirements for what constitutes a valid message sequence. After a long session, your history may contain:
- Empty assistant messages — left behind when a response was interrupted before content arrived
- Orphaned tool calls — the assistant requested a tool but the result was never received (cancellation, network interruption, etc.)
- Consecutive messages from the same role — an artifact of certain error recovery paths
Any one of these can cause the new provider's API to return a 400. The session would appear broken even though the underlying content is intact.
Canonicalization fixes this before the new model ever sees the history, in three passes:
- Pass 1 — Remove empty assistant messages.
content=""with no tool_calls triggers "non-empty content" errors. Strip them first. - Pass 2 — Merge consecutive user messages. After Pass 1 you may end up with two adjacent user messages. Identical ones are deduplicated; different ones are joined with
\n. - Pass 3 — Trim unpaired tool calls. Scan the last 5 assistant tool-call messages, find any
tool_call_idwith no matching tool response, and truncate from that point.
The cleaned history is loaded into the new Runner. Tool config is restored (toolChoice: auto). If the new model supports extended thinking and it was enabled before, it is re-enabled — otherwise it is automatically disabled for that model.
Result: the new model sees a complete, clean conversation. Content is fully preserved. The provider-specific quirks from the old session are gone.
5. Three real-world scenarios
Scenario 1: Draft fast, refine with depth
You're writing a technical spec for a new API. The structure is straightforward — resource definitions, endpoint signatures, error codes. You want to get the draft out quickly without burning expensive reasoning capacity on scaffolding work.
You start with a fast, cost-efficient model. It handles the scaffolding well: proposes the initial endpoint list, drafts the request/response schema, sketches the error taxonomy. Thirty messages in, you have a solid skeleton.
Now the hard part: inconsistencies in the auth model, edge cases in the pagination design, questions about backward compatibility. This is where you want the strongest reasoning you can get.
You switch to your most capable model — right there, same session. It picks up the draft exactly where it is. You ask it to audit the auth design. It reads the full thirty-message history of decisions already made, flags two contradictions you hadn't noticed, and proposes a cleaner approach that's consistent with the patterns already established.
You didn't restart anything. You didn't paste the spec into a new window. The fast model did the work it was good at; the powerful model did the work it was good at. Total cost: a fraction of what it would have cost to run everything on the capable model from the start.
Scenario 2: Hit a capability wall mid-session, keep going
You're in a debugging session. A Go service is misbehaving under load — requests are stalling and you suspect a goroutine leak. You've been using a model with strong reasoning capability. Over the past fifteen messages it has traced the issue to a goroutine that's consuming from a message queue without a timeout.
Now you need to fix it: edit three files, run the test suite, check that the queue consumer behavior changes as expected. Your current model doesn't support tool calls.
You switch to a model with tool access. Same session, same history.
The new model can see the full diagnostic trail — the stack traces you explored, the hypothesis you validated, the exact files you identified. It doesn't need any re-explanation. It goes straight to the implementation, runs the tests, confirms the fix holds.
No re-diagnosis. No "can you summarize what we found?" The context is already there because the history is already there.
Scenario 3: Cost-aware multi-phase review
Your team has a batch of pull requests queued for AI-assisted review. Most are mechanical — check for common patterns, flag style violations, confirm test coverage. A few are genuinely complex — architecture decisions, security-sensitive changes, subtle logic in concurrent code.
You work through the batch in a single session. For the routine reviews, you stay on a fast, cost-effective model. It handles the pattern-matching well. When you hit a PR that touches the auth layer and the billing service simultaneously, you switch to your highest-capability model for that one.
Then switch back.
The session thread keeps the full record of every review, every flag, every comment. The model switches are invisible to anyone reading the session history — they just see a coherent thread of review work. The cost profile matches the actual complexity of each piece of work, not the worst-case complexity of any single piece.
6. Why the model is a parameter, not an identity
The design decision here is that the session, not the model, is the persistent entity.
Your conversation state lives in the session. The model is a parameter of how the next message gets processed. Switching the model doesn't change whose conversation this is — it's still the same conversation; only the next message gets handled by a different engine.
This means the model selector in Helix works differently from a provider switcher in other tools. You're not starting a "new conversation with Claude" — you're continuing the same conversation, but with a different engine processing the next message.
The WebSocket protocol reflects this. Every outbound message carries the current model ID. The backend checks it against the session's current model on each message and runs the appropriate switch path before sending to the LLM. There is no separate "switch model" API call. The switch and the message are one atomic operation.
Every message over WebSocket:
{
"type": "message",
"content": "...",
"model": "builtin-anthropic:claude-sonnet-4-5", ← current selection
"req_id": "req_xxx"
}
Backend on receipt:
if msg.Model != session.CurrentModel {
runSwitchPath(session, msg.Model) // one of the three paths above
}
// then process message with (possibly new) model
A side effect of this design: you can change models as often as you want. There is no accumulated penalty for switching back and forth. Every switch is evaluated fresh against the current state. There is no "the session gets weird after three switches" trap — because the switch itself carries no accumulated state.
It also means the session's continuity does not depend on "not changing models." Continuity comes from the message history stored on the session; the model is just the component consuming that history and producing the next response.
7. Get started
Model switching requires no configuration. The model selector is in the chat toolbar of every Helix session.
A few things worth knowing before you use it:
- Switch any time. There is no right or wrong moment. The switch takes effect on the next message you send.
- History is fully preserved. The new model sees everything that happened before it — not a summary, the actual history.
- Tool configuration carries over. The new model gets the same tool access, provided it supports tool calls.
- Thinking mode follows capability. If the new model supports extended thinking and you have it enabled, it continues. If it doesn't, it's disabled automatically for that model.
- Switching is free. There's no cost to the switch itself — only to the messages you send after it.
The session is the conversation. The model is just whichever engine is running it right now.
Go deeper into Helix
Model switching is one concrete expression of a broader stance in Helix: the session is the persistent entity. The same thinking shows up in several larger places in the product:
- 🧩 Manager Mode — treating an Agent as a system, not a conversation
- 🌿 Automatic Worktree — Agents work on isolated branches and never touch your main
- 🔒 HelixVM — putting Agents inside a local VM sandbox
- 🚀 Introducing Helix — not a smarter AI assistant, an AI coworker that ships
Or just open Helix, grab a session that's currently stuck, and switch to a different model — see whether it picks up where the last one left off.