对话中途切换模型:无需重启,不丢上下文


想换一个更便宜的模型?请把需求重新粘贴一遍。
想换一个更强的模型?请把上下文从头讲一遍。
这是大多数 AI 工具今天的现状。
会话中途切换模型听起来很简单。但在大多数系统里,它的真实含义是:从头开始。
用户在对话开始时选定一个模型,然后构建上下文 —— 二十条消息、十多次工具调用、一堆文件读取。等到他意识到这个模型太慢、太贵,或者缺少需要的能力时,摆在面前的选择只剩两个:要么放弃当前会话从头来过,要么继续用「不对的工具」勉强干完。
Helix 不是这样设计的。
在 Helix 里,模型是会话的当前引擎,不是会话的身份。用户可以在对话的任意位置切换模型 —— 同一段历史、同一组工具配置、同一份思考上下文,只是下一条消息开始换一个引擎来跑。
这是 Helix 介绍文章 里那句核心立场的具体落地:「会话才是连续性的单位,模型只是当前的引擎」。
1. 一上来就锁定模型,是一种结构性的浪费
每个模型的成本与能力权衡都不同。
一个非常擅长在复杂架构问题上深度推理的模型,用来快速起草工作时就太贵;一个能流畅处理日常编辑的便宜快模型,在需要跨大型代码库进行多步推理时就力不从心。
真实工作往往不会整齐地落在某一类。
一次编码会话经常以「探索」开头 —— 读文件、理解结构、提澄清问题 —— 而以更需要能力的实现工作收尾。或者反过来:先用强模型啃硬骨头,然后想换一个更快的模型来收尾。
传统做法迫使用户只能在会话开始时做出选择 —— 而那时他对任务真正需要什么的了解最少。
这不是模型本身的问题,是产品形态把「选模型」放错了时机。
2. Helix 中的模型切换:传统方式 vs Helix 方式
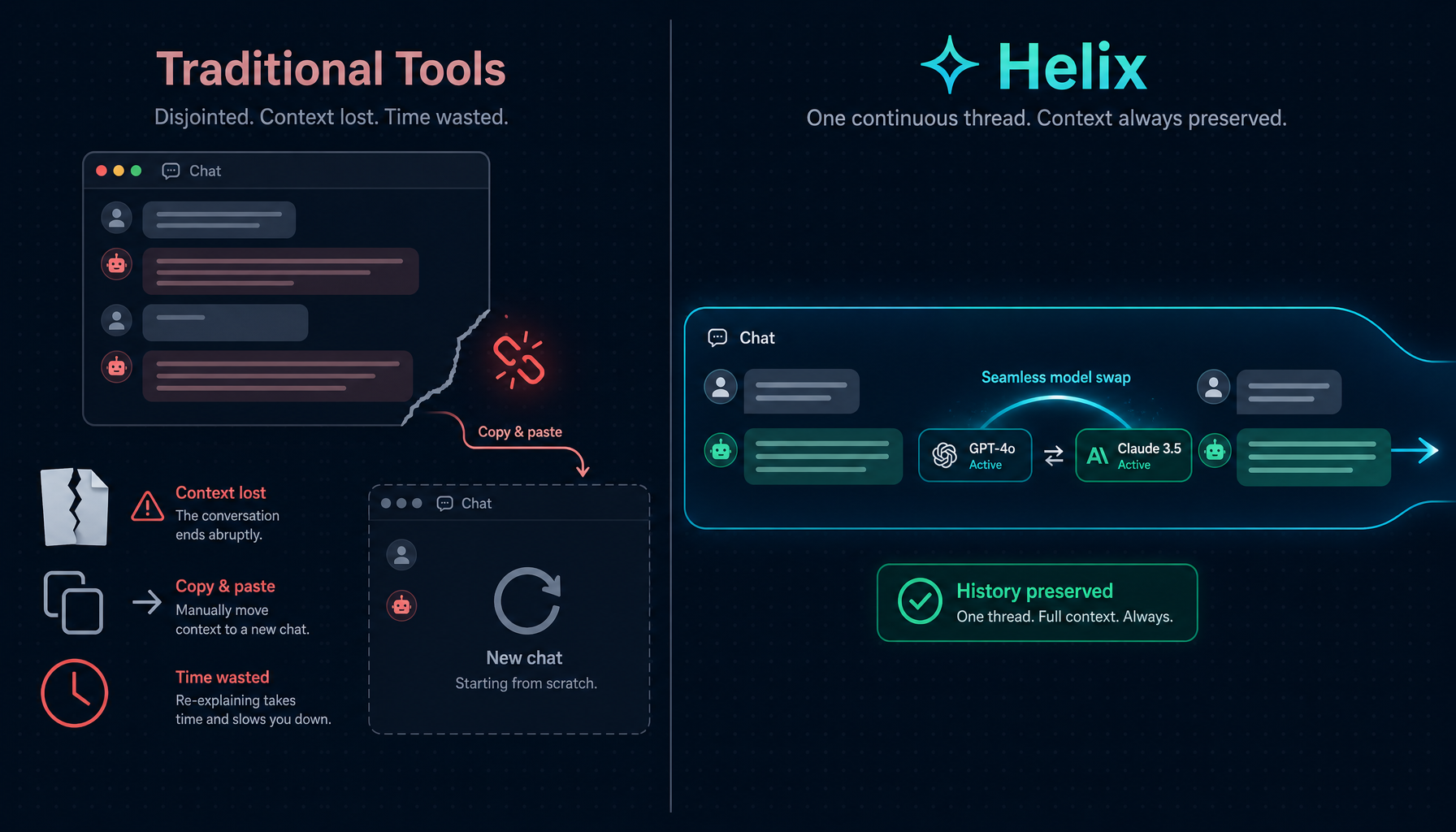
在 Helix 中,模型选择器始终位于聊天工具栏。用户可以在对话的任何时刻切换它。
下一条发出的消息会使用新模型 —— 同时拥有此前发生的一切上下文。
无需重置。无需重新讲解。无需「让我先把前情说一遍」。
对话历史会随用户跨越模型切换。这并不是 prompt injection 式的把先前消息总结后再交给新模型,而是把真正的消息历史直接转交给新模型,让它拥有与从一开始就在对话中等同的上下文深度。
更进一步,Helix 把模型切换暴露在三个不同的粒度上:
- 默认模型:账号或工作区级别的默认引擎;新会话从这里继承
- 会话内切换:在某条对话中途按需替换引擎,下一条消息生效
- 工具调用级别:某些专用工具(比如代码补全、轻量提问)可以使用比主对话更便宜的模型,由 Agent 系统自动路由
三个粒度共享同一套底层切换机制,只是触发位置不同。
3. 三种切换路径
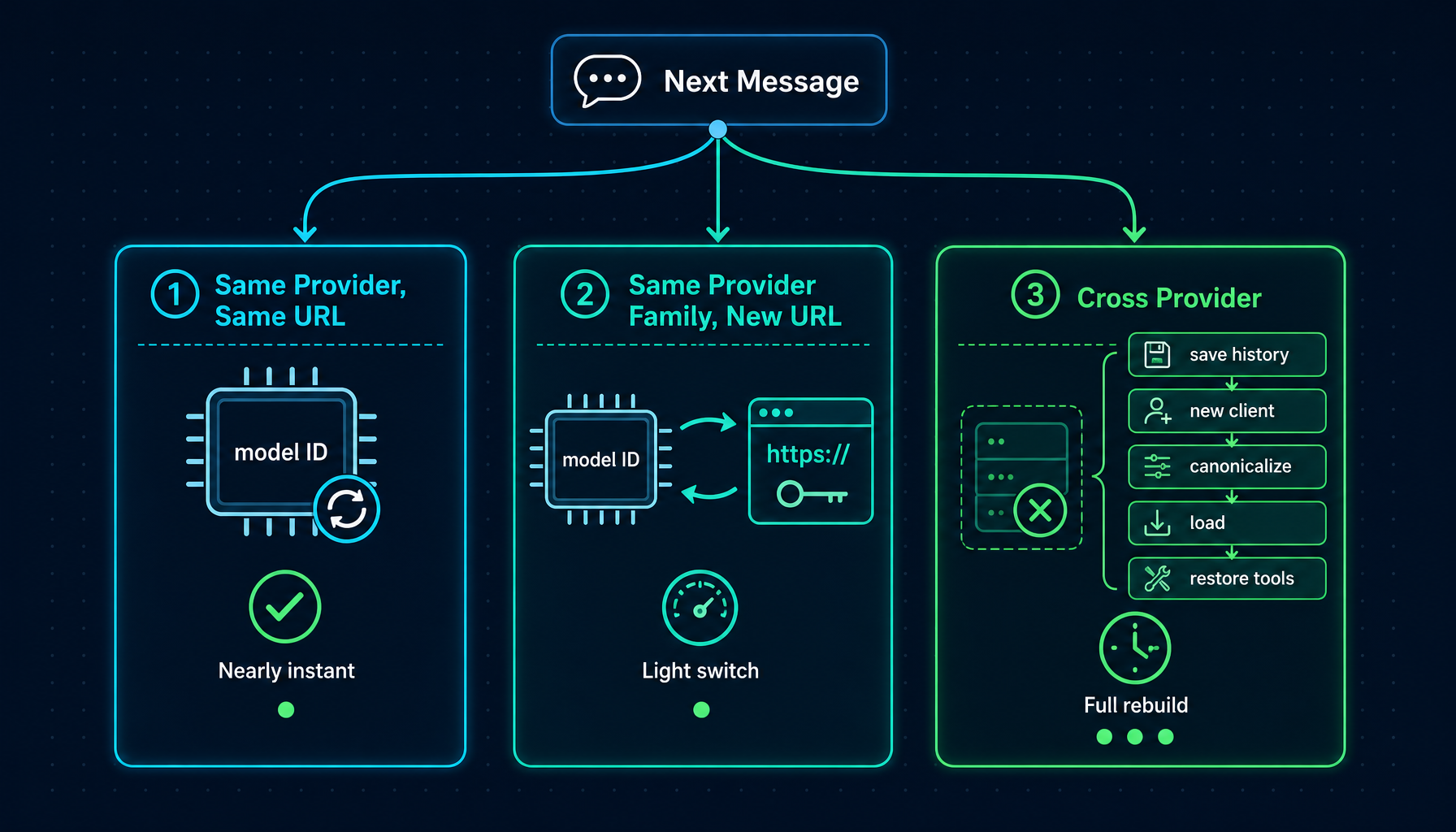
并非所有的模型切换都是一回事。Helix 根据底层需要变更的内容,分别处理三种情境。
同一 provider,同一 base URL(例如 gpt-4o → gpt-4.1):LLM 会话原地更新模型 ID。已有的连接、工具配置和消息历史保持不变。几乎是瞬时完成。
同一 provider 家族,不同 base URL(例如在两个自定义 OpenAI 兼容端点之间切换):会话会更新模型 ID、base URL 和 API key,无需重建 Runner。
跨 provider 切换(例如 GPT-4o → Claude Sonnet,或任意模型 → CLI 模式):会进行完整的 Runner 重建。消息历史会从旧 Runner 中提取出来,做一次净化,然后加载到新 Runner 中。这是最有趣的一种情况,也最值得深入了解。
在工程层面,这意味着「轻量切换」和「重量切换」走的不是同一条代码路径,但对用户而言它们都只是「在工具栏点一下另一个模型」 —— 这是 Helix 在底层为用户隐藏复杂度的方式之一。
4. 对话历史在跨 provider 切换时会被怎样处理
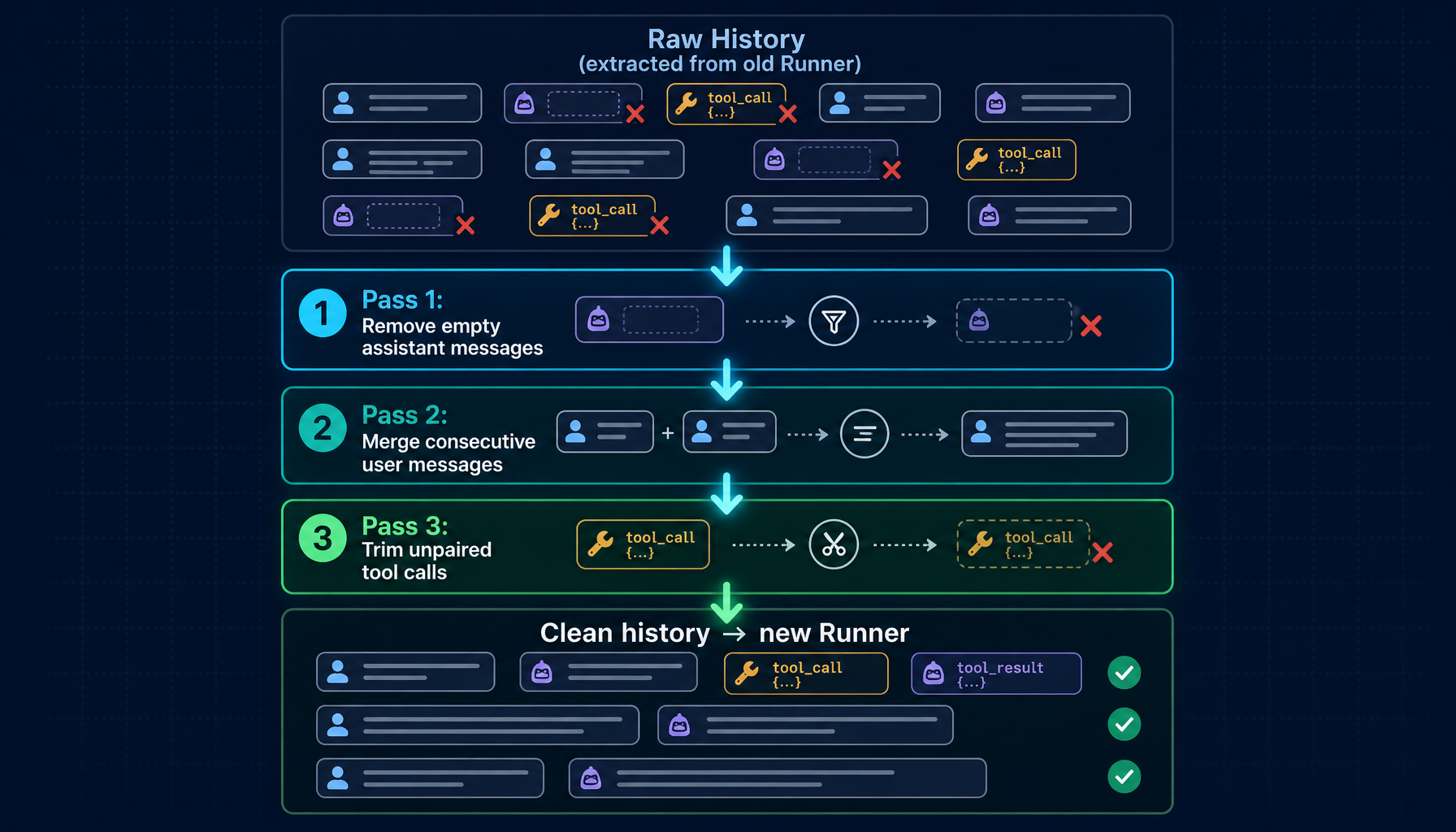
当用户跨 provider 切换时,Helix 会先对消息历史做一次规范化(canonicalization)处理,然后再交给新模型。
为什么有必要这样做?
不同 provider 对「合法消息序列」的细节要求略有不同。在长会话之后,历史里可能会包含:
- 空的 assistant 消息 —— 在内容尚未到达就被打断的响应留下的残骸
- 孤立的 tool call —— assistant 请求了某个工具,但结果从未到达(中途取消、网络中断等)
- 同一 role 的连续消息 —— 某些错误恢复路径产生的副产物
只要存在其一,新 provider 的 API 就会返回 400。即便底层内容完整,会话看起来也像坏掉了。
规范化在新模型看到历史之前就把这些问题处理掉,分三遍:
- Pass 1:移除空的 assistant 消息 ——
content=""且没有 tool_calls 的消息,会触发「non-empty content」错误,先剔除 - Pass 2:合并连续的 user 消息 —— Pass 1 之后可能出现两条相邻的 user 消息;相同则去重,不同则用
\n连接 - Pass 3:修剪孤立的 tool call —— 扫描最近 5 条 assistant tool-call 消息,找出任何没有对应 tool 响应的
tool_call_id,从该点起截断
最后,Helix 把清理过的历史加载到新 Runner,恢复工具配置(toolChoice: auto),如果新模型支持扩展思考且原会话开启了思考模式,也会重新启用。
结果是:新模型看到的是一段完整、干净的对话。内容被完整保留,旧会话留下的 provider 特有怪癖也被清理掉。
5. 三个真实场景
场景 1:用快模型起草,再用强模型打磨
用户正在为一个新 API 写技术规范。结构本身并不复杂 —— 资源定义、端点签名、错误码。他希望尽快产出初稿,不想把昂贵的推理能力浪费在搭骨架的工作上。
他先用一个又快又便宜的模型。它把脚手架处理得很好:列出初版端点、起草 request/response schema、勾画错误分类法。三十条消息后,他已经有了一个扎实的骨架。
接下来才是难点:auth 模型中的不一致、分页设计中的边界情况、向后兼容性的疑问。这正是他想要最强推理能力的地方。
他直接切到能力最强的模型 —— 同一会话,无需新开。它准确地接续在他停下的位置。他让它审查 auth 设计,它读完前三十条消息中已经做出的所有决定,指出他没注意到的两处矛盾,并提出一个与已有模式保持一致的更干净方案。
他没有重启任何东西,也没有把规范粘贴到一个新窗口。 快模型干它擅长的活,强模型干它擅长的活。总成本仅是从一开始就用强模型的一小部分。
场景 2:会话中途撞上能力上限,继续推进
用户在调试一个 Go 服务的负载异常 —— 请求开始卡住,他怀疑有 goroutine 泄漏。过去十五条消息中他一直在用一个推理能力很强的模型。它把问题追踪到了一个从消息队列消费、却没有 timeout 的 goroutine。
接下来需要修复:编辑三个文件、跑测试套件、确认队列消费者的行为如预期发生变化。但他当前的模型不支持 tool call。
他切换到一个支持工具访问的模型。同一会话,同一历史。
新模型能看到完整的诊断轨迹 —— 探查过的 stack trace、验证过的假设、定位到的具体文件。它不需要任何重新讲解。它直接进入实现阶段,跑测试,确认修复有效。
无需重新诊断,无需「能否帮我总结一下我们发现了什么?」上下文已经在那里,因为历史已经在那里。
场景 3:成本敏感的多阶段评审
用户的团队有一批 PR 排队等 AI 协助评审。大多数都是机械性的 —— 检查常见模式、标记代码风格违规、确认测试覆盖。少数是真正复杂的 —— 涉及架构决策、安全相关改动,或并发代码中微妙的逻辑。
他在同一会话中处理整批 PR。对常规评审,他保持使用快速且性价比高的模型;它在模式匹配上表现良好。当遇到一个同时改动 auth 层和 billing 服务的 PR 时,他为这一个 PR 切到能力最强的模型。
然后再切回来。
会话线索保留了每一次评审、每一个标记、每一条评论的完整记录。模型切换对任何阅读这条会话历史的人都是不可见的 —— 他们只看到一条连贯的评审线。成本结构匹配的是每段工作真实的复杂度,而不是其中最复杂那一段的最坏情况。
6. 为什么模型是参数,不是身份
这里的设计取舍是:会话才是持久实体,模型不是。
用户的对话状态存在会话里。模型只是「下一条消息如何被处理」的一个参数。换一个模型,并不会改变这段对话是「谁的对话」 —— 它仍然是同一段对话,只是下一条消息换了一台引擎来处理。
这意味着 Helix 中的模型选择器和其他工具的 provider 切换器工作方式不同。用户不是在「用 Claude 开启一段新对话」 —— 他是在继续同一段对话,只是用了一个不同的引擎来跑下一条消息。
WebSocket 协议体现了这一点。每条出站消息都会带上当前模型 ID。后端在每条消息上都会与会话当前模型对照,并在发往 LLM 之前执行相应的切换路径。不存在单独的「切换模型」API 调用。切换和消息是同一个原子操作。
Every message over WebSocket:
{
"type": "message",
"content": "...",
"model": "builtin-anthropic:claude-sonnet-4-5", ← current selection
"req_id": "req_xxx"
}
Backend on receipt:
if msg.Model != session.CurrentModel {
runSwitchPath(session, msg.Model) // one of the three paths above
}
// then process message with (possibly new) model
这一设计的副作用是:用户想切多少次都行,没有累积代价。每次切换都基于当前状态重新评估。不存在「切了三次之后会话就乱了」这种陷阱 —— 因为切换本身没有积累的状态。
它也意味着会话的「连续性」不依赖于「不换模型」。连续性来自会话存储的消息历史;模型只是负责消费这段历史、产出下一条响应的那个组件。
7. 开始使用
模型切换不需要任何配置。模型选择器位于每个 Helix 会话的聊天工具栏中。
使用前有几点值得知道:
- 任意时刻都可切换。 没有所谓正确或错误的时机。切换会在用户发送的下一条消息生效。
- 历史完整保留。 新模型看到的是它之前发生过的一切 —— 不是摘要,而是真实的历史。
- 工具配置会延续。 只要新模型支持 tool call,它会获得同样的工具访问权限。
- 思考模式跟随能力。 如果新模型支持扩展思考且用户已开启,它会继续启用;不支持则会自动为该模型关闭。
- 切换本身免费。 切换动作不产生额外成本 —— 只有用户切换之后发送的消息会计费。
会话即对话。模型只是当前正在驱动它的那台引擎。
想深入了解 Helix 的其他部分?
模型切换只是 Helix 把「会话当作持久实体」这一立场的一个具体表现。同一套思路在产品里还有几个更大的落点:
- 🧩 Manager Mode:把 Agent 当成系统而不是对话
- 🌿 Automatic Worktree:Agent 在隔离分支上工作,不污染主线
- 🔒 HelixVM:把 Agent 放进本地虚拟机沙箱
- 🚀 Helix 总览:不是更聪明的 AI 助手,而是能交付的 AI 同事
或者,直接打开 Helix,把现在卡住的那段会话拿来 —— 切换一个模型试试看它能不能接得住。