Introducing Helix — Not a Smarter AI Assistant, but an AI Teammate That Actually Delivers

Most AI coding assistants keep getting smarter at answering.
They've barely moved at delivering.
That's what Helix is built to change.
Over the past year, AI coding assistants have multiplied. Models got smarter, context windows grew longer, reasoning chains went deeper — and yet, for people actually running real engineering tasks through them, the lived experience didn't improve nearly as much.
They all follow a similar arc. The first session feels magical: it writes a function that almost looks production-ready. After a few weeks of real use, it starts to feel off. After a few more weeks, the pattern becomes clear: what these tools are really good at is answering beautifully, not getting things done.
Ask one to "refactor the auth module." It returns a polished, well-structured explanation: "Here's the new AuthService design…" — and then what? Editing the code, running the tests, fixing the build, committing, merging — that's still on the user.
It hands back an answer, not an outcome.
Real work needs outcomes. A cross-module refactor that actually runs to completion. A test suite that turns green. A commit that lands on main. A board where progress is visible to the team. None of that involves "saying it well."
That's the problem Helix was built to solve.
Helix isn't another AI assistant that answers questions — it's designed to be an AI teammate that actually delivers.
1. The ceiling of single-thread chat
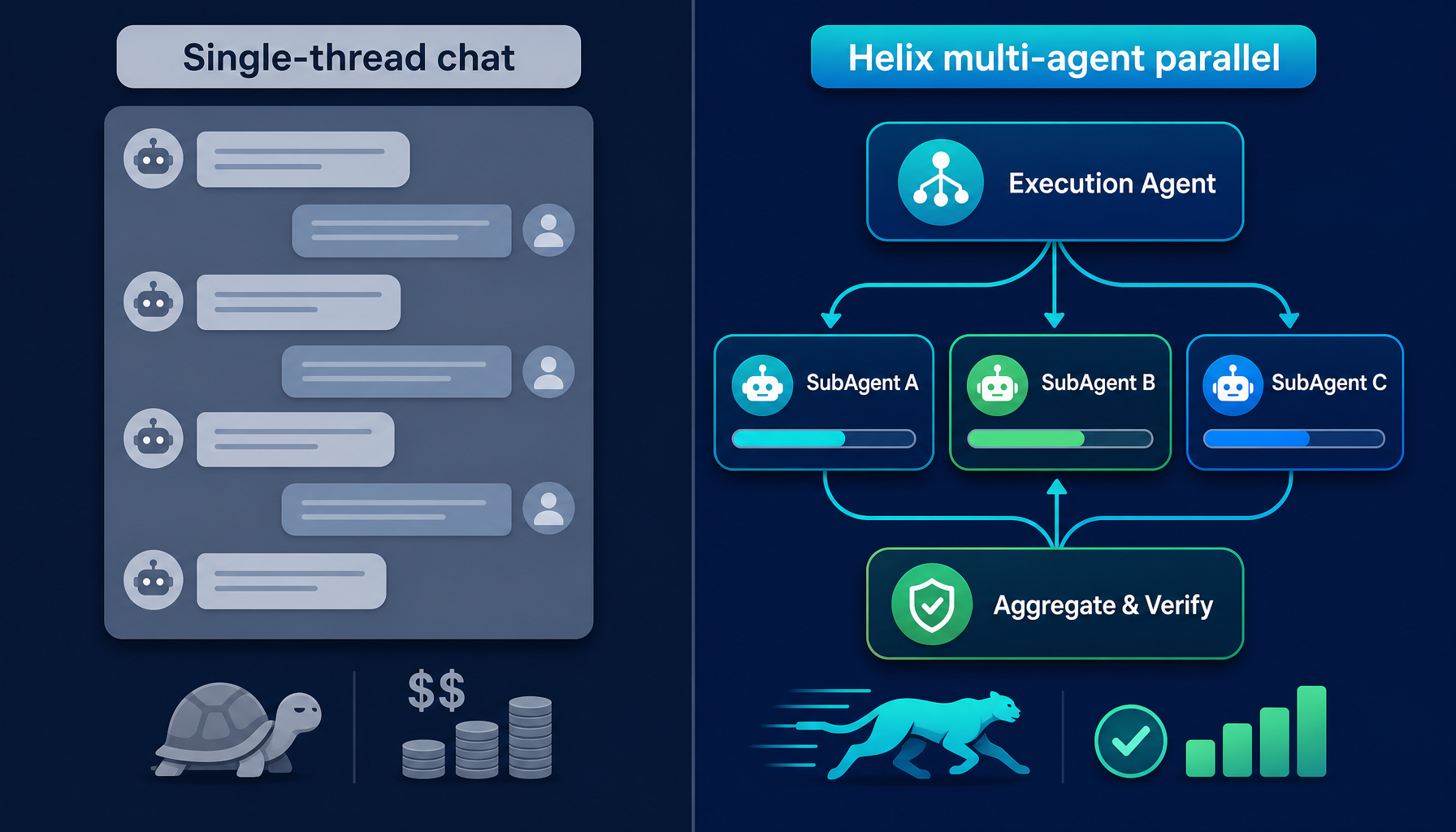
Most AI coding tools are, at heart, just a smarter chat box.
The user talks, the model replies. Every piece of work gets compressed into the same conversational thread: understanding intent, exploring code, writing code, running tests, explaining errors, summarizing progress — all in sequence, all in one timeline.
The real problem isn't model capability. It's that the chat-box shape structurally can't carry complex work:
- A task spans three modules; thirty turns in, the user has lost track of what the agent promised and what it skipped.
- Long sessions get expensive and fragile: every new message replays the entire history through the model, costs scale linearly, but quality often doesn't.
- The user can't see what the agent is actually doing. It says "done" — open the IDE, and the work is incomplete, or wrong.
- Tasks cross local and remote environments; every switch means re-explaining context.
None of this is the model's fault. It's the ceiling of "conversation" as a shape.
How do human engineering teams handle problems like this? They split the work. A PM keeps the goal. Engineers implement. Multiple people work on sub-tasks in parallel. A board makes progress visible.
AI agents should do the same.
2. Helix treats agents as a system, not a conversation
The core stance of Helix can be put in one sentence:
The session is the unit of continuity; the model is just the current engine. The task is the unit of delivery; the conversation is just the record of how it happened.
Once the frame shifts from "who am I talking to" to "how does this task ship," the rest follows naturally:
- Tasks can be decomposed, so there should be Manager + Execution + SubAgent role separation.
- Sub-tasks are independent, so they should run in parallel instead of serially queuing.
- Long tasks inevitably accumulate context, so Cache + Compact should protect quality and contain cost.
- Real work moves between local and remote, so a workspace should be an independent execution boundary, not tied to a specific model or chat.
The rest of this post unpacks each of those.
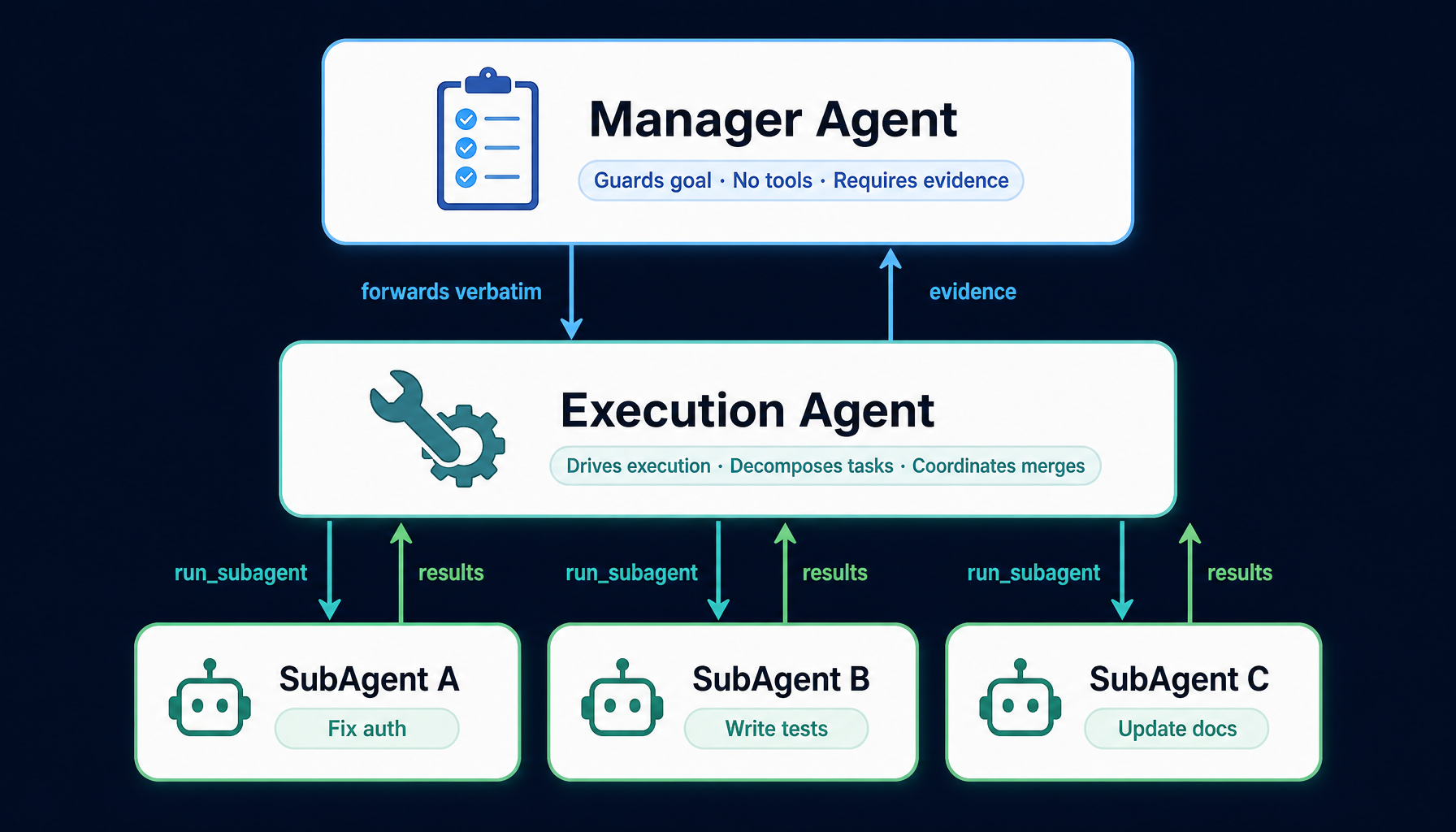
3. Three-layer multi-agent architecture: agents that constrain each other
The most damaging failure mode of single-agent systems is scope drift. The user says "refactor the auth module," and three minutes later the agent has also "optimized" five unrelated utilities, swapped in a new error-handling library, and pulled in a new dependency — then written a thorough summary explaining "why all of this was necessary."
The root cause is direct: a single-agent system never separates "understand what the user asked for" from "decide what to do." Both responsibilities get fused into the same loop, with no guardrail between them.
Helix's answer is to split those responsibilities across different agents, so they can constrain each other.
Manager Agent — guards the goal, never touches code
The Manager doesn't write code, doesn't run shell commands, doesn't call tools. Its single responsibility is this: make sure what gets delivered is what was originally asked for.
It locks the user's original request as a baseline. Every action by the execution layer is evaluated against that baseline for scope creep. And it requires evidence of completion — not "the agent said it's done," but the commit actually in git log, the working tree actually clean, the test output actually green.
Execution Agent — drives execution, decomposes work
This is the layer that actually works. It reads code, writes code, calls tools, runs tests. But it doesn't try to be a hero — it actively breaks work into parallelizable pieces and dispatches them to SubAgents below.
SubAgent — goes deep, runs in parallel
Each SubAgent is an isolated execution context. It focuses on one thing inside its own view of the world, then reports results back to the Execution Agent.
The elegance of this architecture isn't "we have N agents." It's this:
No single agent is responsible for both defining the goal and executing it.
PMs don't write code. Engineers don't redefine requirements. For the first time, an AI system has role boundaries that resemble a real team.
For a deep dive into how the three-layer architecture defends scope in complex tasks, see Manager Mode.
4. Parallel scheduling: three tasks in the time of one
A chat box is a serial interface. Real work is often parallel.
Once the Execution Agent decomposes a task, Helix actually runs the sub-tasks concurrently — not just lists them, but dispatches and executes them at the same time.
Concrete example. The user says: "Migrate auth, payment, and notification services from REST to gRPC."
In traditional chat-based AI, this becomes:
user → model → auth migrated → user reviews → user says continue →
model → payment migrated → user reviews → user says continue → ...
In Helix it becomes:
Execution Agent
├─→ SubAgent A: auth migration [parallel]
├─→ SubAgent B: payment migration [parallel]
└─→ SubAgent C: notification migration [parallel]
↓
Execution Agent: collect → verify → deliver
Three independent pieces of work, finished in roughly the time of one.
Parallelism isn't just a speedup. It changes the waiting experience: the rhythm of "say something, wait, say something else, wait again" gets replaced by "state the full goal once, watch multiple tracks advance simultaneously."
More importantly — because the Manager Agent guards the upstream boundary, the "loss of control" usually associated with parallel agents is contained. SubAgents can run as fast as they want; the Execution Agent still merges their outputs in sequence, and the Manager still validates the integrated delivery against the original scope.
Faster, but the boundary holds.
5. Context management: a 50-turn task that feels like a 5-turn one
The most demoralizing thing about long sessions is that the deeper progress gets, the worse the experience becomes.
In the first few turns the AI is fast and accurate. After dozens of turns, the whole session feels heavy — every message reloads the entire history through the model, latency creeps up, quality drifts down, and the token bill starts to hurt.
Helix counters that curve with two mechanisms:
KV Caching. Large tool outputs — file reads, shell command results, search results — are cached. The agent knows "that history is sitting there, retrieve it when needed" instead of re-sending it verbatim with every model request.
Auto-compression. Once history exceeds a threshold, Helix compresses older sections into concise summaries and slides the active window forward. The agent still understands what happened; the user doesn't pay token cost for the entire transcript.
Both are enabled by default and invisible to the user. The goal isn't to look technically sophisticated — it's to make a 50-turn complex task feel as responsive as a 5-turn quick one.
6. Multi-workspace: local and remote stop being two separate products
Many AI tools assume the user works in one place — a local repo, a cloud IDE, or a remote dev container. The moment work crosses that boundary, the experience breaks.
Helix treats a workspace as an independent execution boundary.
Within a workspace, the sessions running there, the code those sessions write, the tools they call, the ports they reach — all stay inside that workspace's boundary. The user can have a local repo, a remote dev environment, an ephemeral VM, and a Docker container open at the same time. They're independent, but all driven by the same agent system.
That means:
- "An experimental task on the laptop" and "a real deployment task on the remote machine" can run at the same time.
- Switching workspaces carries session state, model choice, and connection config along — no re-explaining.
- When something goes wrong, the workspace is a natural isolation unit — one workspace blowing up doesn't affect the others.
This idea extends further in HelixVM: when the workspace itself is a virtual machine, the agent's execution boundary becomes a safety boundary as well.
And at the source-control layer, Helix provides Automatic Worktree: the agent never touches the user's main branch directly. All changes happen on isolated branches, with code review gating the merge back to main.
7. The commitments Helix makes to itself
By now, the way Helix talks about agents probably feels different from most AI products.
Helix doesn't lean on phrases like "smarter model," "longer context," or "deeper reasoning." The team has seen too many products where the model keeps getting stronger but the user experience barely moves — great demo videos, same old problems in real use.
Helix holds itself to a short, plain list:
- Not a pretty demo — a real task that actually runs to completion. A task that "looks done" doesn't count. A commit on main with a green test run does.
- Not a smooth conversation — a change that actually lands. What matters in the end is whether the commit exists in
git log, not how nicely the chat read. - Not the quality of a single answer — the reliability of the whole delivery. Turn 47 should still behave like turn 1.
- Not the model doing the work for the user — the agent system doing it. The model is the engine; the architecture surrounding it is what shapes the experience.
If someone just wants an AI that answers questions, there are plenty of options out there.
But for people who actually run engineering tasks through AI — the kind of 30-turn task that spans five files, needs parallelism, needs visibility, needs to keep going when something breaks — Helix is built for that.
8. What's coming next
Helix is iterating quickly. On the roadmap:
- Richer evidence views: visualizing what each SubAgent did, which files it touched, which commands it ran.
- Stronger workflow templates and a skill system: turning repeatable engineering patterns — migrations, test coverage, logging instrumentation — into reusable "playbooks."
- Cross-platform desktop parity: bringing macOS, Windows, and Linux experiences to the same level.
- Team collaboration paths: letting humans and agents co-operate on the same task flow.
One thing won't change:
An agent shouldn't be designed as a toy that talks. It should be designed as a teammate that delivers.
Want to try it?
Helix is currently open to beta users.
If the idea that "agents should be designed as an engineering system" resonates, take Helix for a spin on the project the user knows best — and don't pick an easy task. Pick the one that makes them hesitate to hand it to AI again. That's the case Helix really wants to be tested against.