隆重介绍 Helix —— 不是更聪明的 AI 助手,而是能交付的 AI 同事

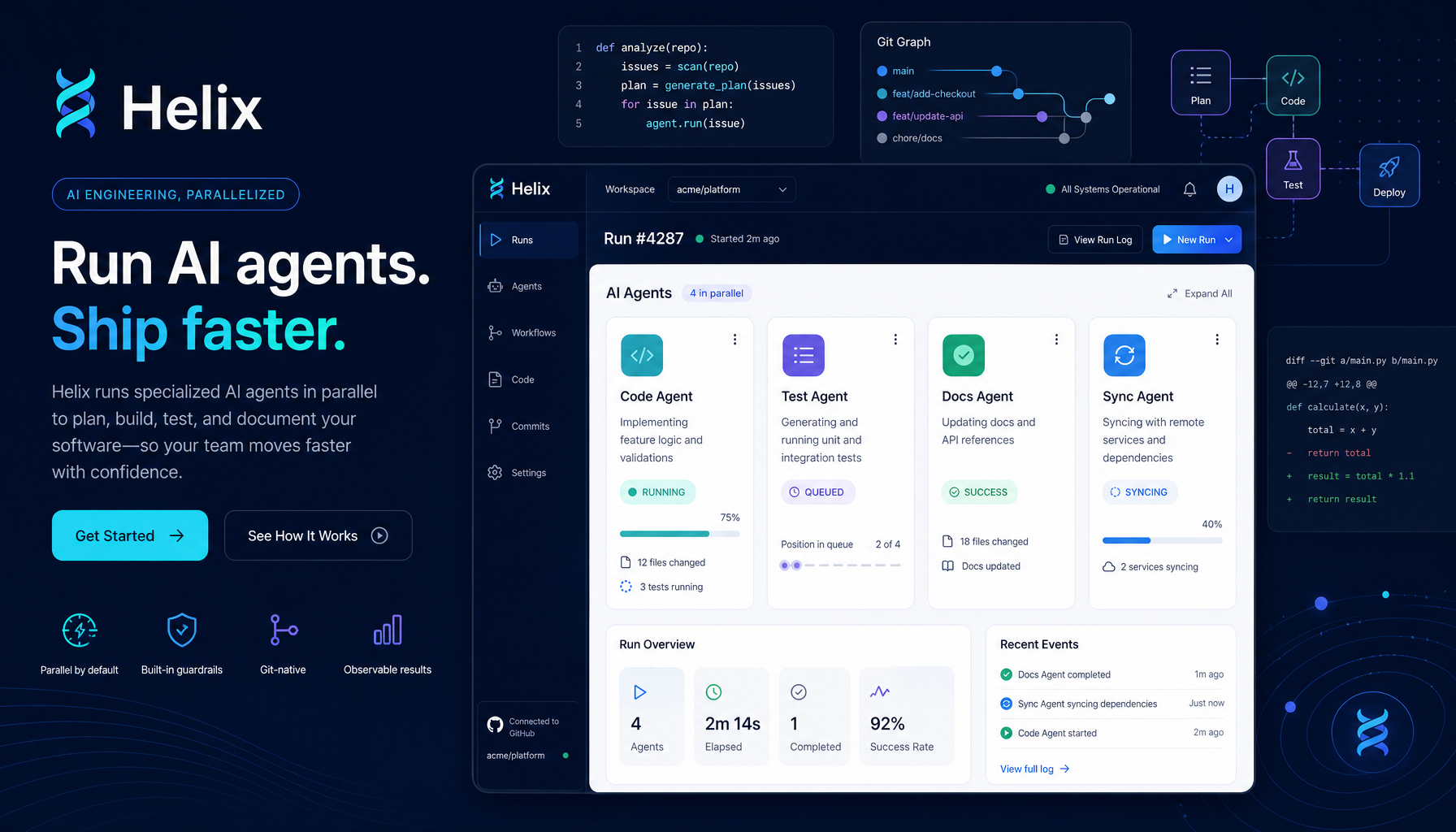
大多数 AI 编码助手在「回答」上越来越聪明,
但在「交付」上几乎没有进步。
这是 Helix 想改变的事。
过去一年里,AI 编码助手层出不穷。模型在变强,上下文窗口在变长,推理能力在变深 —— 但真正在用它们跑工程任务的人,体验上的提升并没有那么显著。
它们都有一个相似的轨迹:第一次用觉得很惊艳,能写出像样的函数;用几个星期之后,开始觉得它们「不太行」;再过一阵子就发现,它们最擅长的其实是回答得漂亮,不是把事做完。
让它「重构认证模块」,它写一段非常工整的回答告诉你「这是新的 AuthService 设计……」。然后呢?真正去改代码、跑测试、修构建、提交、合并的,仍然是用户自己。
它给的是答案,不是结果。
而真实工作场景需要的恰恰是结果:把一个跨多个文件的重构跑完,把测试跑通,把代码提交合并到主分支,把进度对齐到团队的看板 —— 没有「漂亮地说一段话」这一步。
这就是 Helix 想解决的问题。
Helix 不是又一个会回答的 AI 助手 —— 它被设计为一个能交付的 AI 同事。
1. 单线程对话的天花板
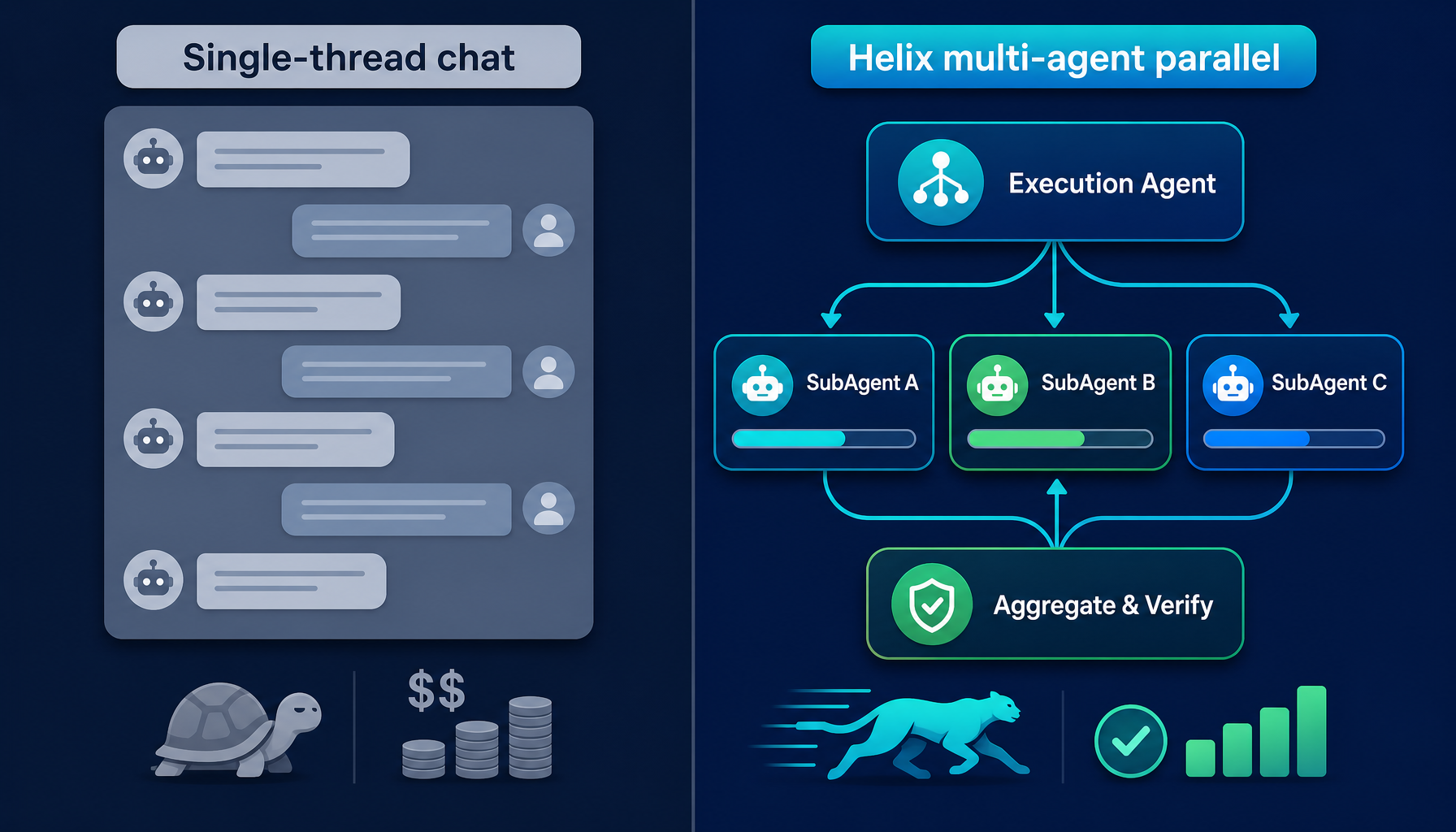
绝大多数 AI 编码工具,本质上都是一个「更聪明的聊天框」。
用户和模型一来一回。模型读用户的话,给一段回答。在这个范式里,所有事情都被压缩进同一条对话:理解意图、查代码、写代码、跑测试、解释报错、总结进度,全部串行进行。
这个模型最大的问题不是能力差,而是它结构性地撑不起复杂任务:
- 一个任务跨三个模块,单条对话来回 30 轮还没收尾,用户已经记不清 Agent 之前承诺过什么、跳过了什么
- 长会话变得又贵又脆:每多发一句话,整段历史都要重新喂进模型,价格线性上涨,质量却不一定线性提升
- 用户看不到 Agent 真正在做什么。它说自己「完成了」,可打开 IDE 一看,根本没改完 —— 或者改了别的
- 任务跨本地和远端,每切一次环境就要重新搭一遍上下文
这些都不是模型的错,而是「对话」这个形态本身的天花板。
人类工程团队怎么解决这类问题?答案是拆分。会有 PM 守目标,会有人做实现,会有人并行做子任务,会有看板让进度可见。
AI Agent 也应该这么做。
2. Helix 把 Agent 当成一个系统,不是一个对话
Helix 的核心立场可以用一句话概括:
会话才是连续性的单位,模型只是当前的引擎;任务才是交付的单位,对话只是过程的记录。
把视角从「在跟谁聊天」换成「这个任务怎么交付」之后,很多事就自然了:
- 既然任务可拆,就应该有 Manager + Execution + SubAgent 的角色分工
- 既然子任务独立,就应该并行执行而不是串行排队
- 既然长任务必然积累上下文,就应该有 Cache + Compact 来保住质量、压住成本
- 既然真实工作在本地和远程之间切换,就应该让工作区是一个独立的执行边界,而不是和模型/会话绑死
接下来一项一项展开。
3. 三层多 Agent 架构:让 Agent 互相约束
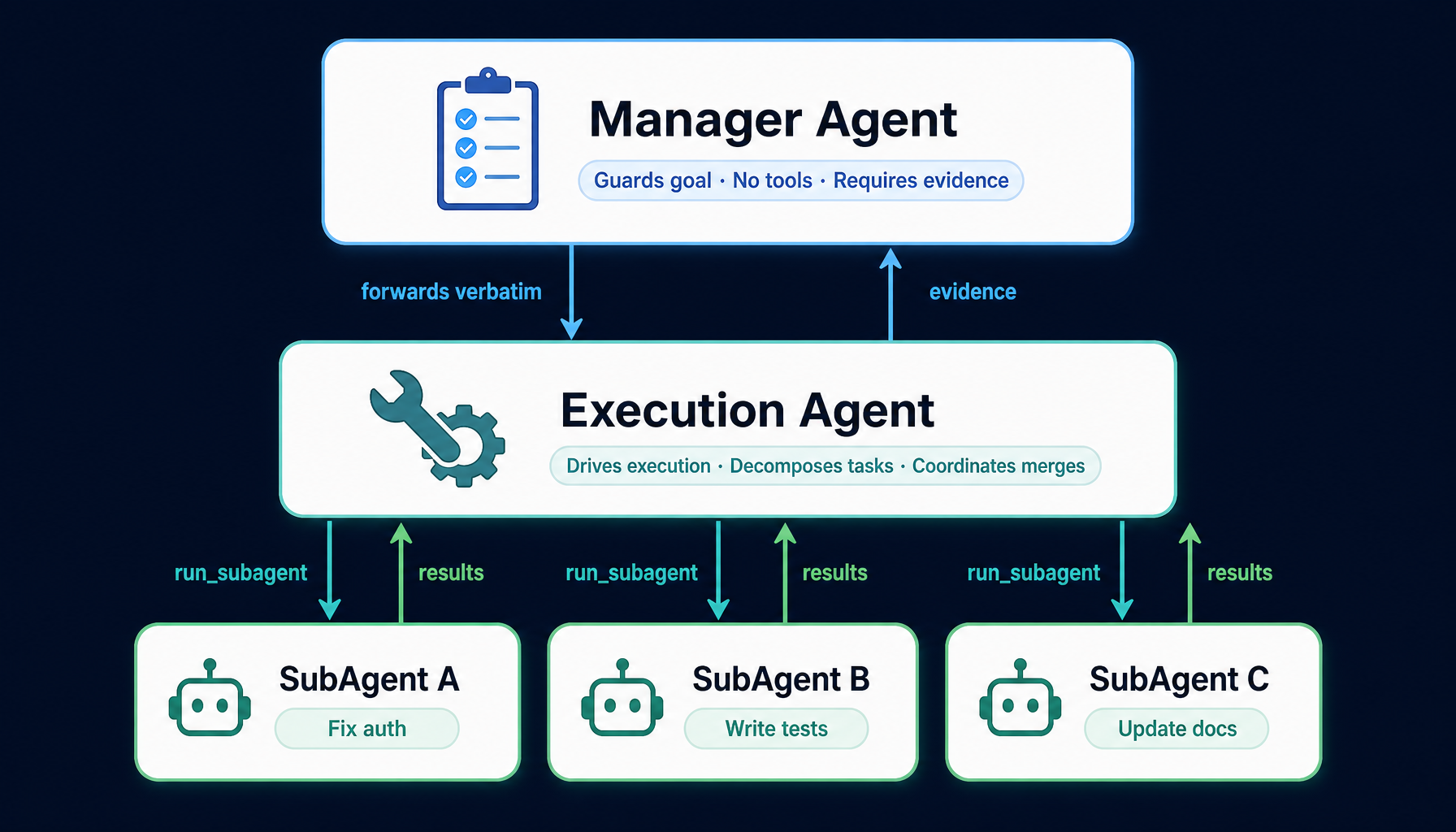
单 Agent 系统最致命的缺陷叫 scope drift(范围偏航):用户说「重构认证模块」,三分钟后 Agent 已经顺手优化了五个工具函数、换了一个新的错误处理库、引入了一个新依赖 —— 然后写一段很完整的总结,告诉用户「这一切都是必要的」。
这个问题的根源很直接:单 Agent 系统没有把「理解用户要什么」和「决定它要做什么」分开。理解和执行被压缩到了同一条线,没有任何护栏。
Helix 的回答是把这两件事分给不同的 Agent,让它们互相约束。
Manager Agent —— 守目标,不动手
它不写代码、不跑命令、不调用工具。它的全部职责只有一件事:确保最后交付的,是用户最初要的。
它会把原始需求锁定为基线;执行环节每做一件事,都对照这条基线评估是不是「越界」;最后它要求证据来确认完成 —— 不是「Agent 说完成了」,而是 git log 里真的有那条提交、git status 真的是干净的、测试输出真的是绿色的。
Execution Agent —— 推执行,会拆解
它是真正干活的那一层。读代码、写代码、调工具、跑测试。但它知道自己不是孤军作战 —— 它会主动把任务拆成可并行的小块,派给下面的 SubAgent。
SubAgent —— 钻深度,分头跑
每个 SubAgent 都是一个独立的执行上下文。它在自己的视野里专心做一件事,做完汇报给 Execution Agent。
这套架构最妙的地方,不是「有 N 个 Agent」,而是:
没有任何一个 Agent 同时承担「定义目标」和「执行目标」。
PM 不写代码,工程师不改需求。AI 系统第一次有了类似真实团队的角色边界。
想深入了解三层架构如何在复杂任务中守住范围,请阅读 Manager Mode 深度解读。
4. 并行调度:让一件事的时间跑完三件事
聊天框是一个串行的界面。但真实任务往往是并行的。
Helix 的 Execution Agent 在拆出子任务后,会真的把它们并发跑起来。
举一个具体例子:用户说「把 auth、payment、notification 三个服务从 REST 迁移到 gRPC」。
在传统对话式 AI 里,这会变成:
用户 → 模型 → auth 迁完 → 用户看一下 → 用户说继续 →
模型 → payment 迁完 → 用户看一下 → 用户说继续 → ……
在 Helix 里,它是:
Execution Agent
├─→ SubAgent A: auth 迁移 [并行]
├─→ SubAgent B: payment 迁移 [并行]
└─→ SubAgent C: notification [并行]
↓
Execution Agent 汇总结果 → 验证 → 交付
三件独立的事,在大约一件事的时间里跑完。
并行不仅是性能加速,它还改变了用户的等待体验:原本"提一句,等很久;再提一句,再等很久"的节奏,被替换成"一次给出完整目标,多路推进同步交付"。
更重要的是 —— 因为有 Manager Agent 守在上游,并行带来的「失控风险」被压住了。三个 SubAgent 各自跑得再快,Execution Agent 也要按顺序合并它们的产出,Manager 也要按统一标准验证整体交付。
速度提升,但边界不丢。
5. 上下文管理:让 50 轮任务不比 5 轮慢
长会话最让人崩溃的地方,是进度越深、体验越差。
刚开始几轮,AI 反应快、回答准;几十轮过后,整个会话开始变重 —— 每发一条消息都在重新加载历史,回答变慢,质量下滑,token 账单开始让人心疼。
Helix 用两件事来对抗这个曲线:
KV Caching:那些超大的工具输出 —— 文件读取、shell 命令的结果、搜索结果 —— 会被缓存。Agent 知道某条历史「就放在那里,需要的时候召回」,不需要在每次请求里都把它原文重发给模型。
Auto-compression:当历史超过阈值,Helix 会把更老的部分压缩为简洁摘要,把「活动窗口」向前推进。Agent 仍然记得发生过什么,但用户不必为整段历史付出 token 代价。
这两件事都是默认开启、对用户透明的。
它们的目标不是「显得有技术含量」,而是让一个 50 轮的复杂任务,用起来跟 5 轮的小任务感觉一样轻。
6. 多工作区:让本地和远程不再是「两个产品」
很多 AI 工具默认用户只在一个地方工作 —— 要么是本地仓库,要么是云端 IDE,要么是某个远程 Dev Container。一旦想跨过来,体验立刻断裂。
Helix 把工作区当成一个独立的执行边界。
在一个工作区里跑的会话、它写入的代码、它调用的工具、它访问的端口,都被框在这个工作区的边界内。用户可以同时打开本地仓库、远程开发环境、临时虚拟机、Docker 容器 —— 它们彼此独立,但都用同一个 Agent 体系驱动。
这意味着:
- 可以把"在笔电跑的实验性任务"和"在远端机器跑的真实部署任务"同时跑
- 切换工作区时,会话状态、模型选择、连接配置都跟着切,不需要重新讲解
- 出问题时,工作区是天然的隔离单元 —— 一个工作区炸掉,不影响其他
这个理念在 HelixVM 文章中被进一步延伸:当工作区本身是一个虚拟机时,Agent 的执行边界就同时变成了安全边界。
延伸到代码层面,Helix 还提供了 Automatic Worktree 机制:Agent 不会在用户的主分支上直接动手,而是自动在隔离分支里完成所有改动,通过 Code Review 后才合并回主线。
7. Helix 对自己的承诺
写到这里,读者可能已经发现,Helix 谈论 Agent 的方式和大多数 AI 产品不太一样。
Helix 不太爱用"更聪明的模型""更长的上下文""更厉害的推理"这种词。
因为团队见过太多这样的产品:模型越来越强,但用户体验没什么变化 —— Demo 录得很好看,真用起来还是同样的问题。
Helix 对自己有几条很简单的要求:
- 不是 Demo 漂亮,是真任务跑得通。 一个任务"看起来完成了"不算数,提交到主分支并且测试通过才算数。
- 不是对话流畅,是改动落地。 用户最终在意的是 git log 里有没有那条提交,不是对话里说得有多顺。
- 不是单个回答的质量,是整段交付的可靠度。 哪怕第 47 轮,依然要表现得像第 1 轮一样靠谱。
- 不是模型替用户工作,是 Agent 系统替用户工作。 模型只是引擎,真正决定体验的是它运转的那套架构。
如果用户只是想要一个会回答问题的 AI,市面上的选择已经很多。
但如果用户是那种真的在用 AI 跑工程任务的人 —— 跑过那种连续 30 轮、跨 5 个文件、需要并行、需要观察、需要在出错时能继续追下去的任务 —— Helix 是为这些场景做的。
8. 接下来要做什么
Helix 还在快速迭代。团队正在打磨的:
- 更丰富的证据页面:每个 SubAgent 做了什么、改了哪些文件、跑了哪些命令,都可视化展示
- 更强的工作流模板和 skill 系统:让重复的工程模式(迁移、补测试、加日志)变成可复用的"剧本"
- 跨平台桌面端能力对齐:macOS、Windows、Linux 三端体验拉齐
- 团队协作路径:让人和 Agent 在同一份任务流程中协作
但有一件事不打算变:
Agent 不应该被设计成一个会说话的玩具。它应该被设计成一个会交付的同事。
想试试看?
Helix 目前对内测用户开放。
如果用户也认同"Agent 应该被当作工程系统来设计"这个判断,欢迎用 Helix 跑一个最熟悉的项目 —— 不用挑容易的任务,挑那种让人纠结"要不要再交给 AI 一次"的硬任务。那才是 Helix 真正想被验证的地方。